
Room EQ Wizzard mal anders: Nutzung des RTA-Moduls
Der Room EQ Wizzard (oder kurz: REW) ist mittlerweile ein sehr etabliertes Tool und es gibt zahlreiche Anleitungen wie man ihn nutzt - einfach mal bei Google oder YouTube nach "REW Anleitung deutsch" suchen. Empfehlen möchten wir euch vor allem die gut gemachte Anleitung von Marcel Schlechter (Vertrieb GENELEC).
Bei den meisten Anleitungen wird als "Messart" der Gleitsinus gewählt, unter anderem weil man damit nicht nur den Frequenzgang misst, sondern auch gleichzeitig die Phase, die Klirrkomponenten und die Nachhallzeit. Das ist zwar sehr schön, aber wir möchten euch hier erläutern, wie ihr mit dem t.racks DSP 4x4 Mini Amp möglichst effektiv und intuitiv eure 2- bis 4-Wege Lautsprecher abstimmen könnt - und das geht unserer Meinung nach eben besser (im Sinne von effektiv und intuitiv) im RTA-Modus. Auch hierfür gibt es eine gut gemachte Anleitung von Markus Mehlau (Raumkorrektur mit REW (Room EQ Wizard) und parametrischem Equalizer (PEQ)), auf die wir hier aufbauen wollen.
Wir gehen davon aus, dass ihr die grundlegenden Schritte wie in der Anleitung von Marcel Schlechter beschrieben durchgeführt habt. Für unsere Anwendung muss es kein teures Audio-Interface von RME sein, da tut es auch schon ein BEHRINGER U-Phoria UM2. Und es ist auch kein teures Messmikrofon von EARTHWORKS nötig, sondern es reicht ein BEHRINGER ECM-8000 - aber es muss individuell kalibriert worden sein, d.h. ihr müsst den Messfehler eures Mikrofons kennen (und die Korrekturkurve auch im REW-Hauptmodul unter "Preferences" im Reiter "Cal Files" im Abschnitt "Mic cal files" laden).
Hier mal die Streuung von 254 ECM-8000-Mikrofonen aus unserem Artikel 1000 Mikrofonkalibrierungen - eine Übersicht:
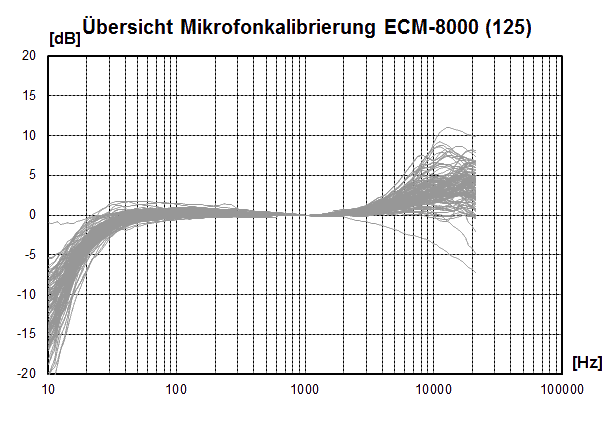

-> bei 10 kHz streuen die 254 gemessenen ECM-8000-Mikrofone also um bis zu +9.5/-3.5 dB!!!
-> wer denkt, sein Mikrofon sei perfekt linear korrigiert die Fehler seines Mikrofons und NICHT die der Lautsprecher!!!
Auf eine Kalibrierung des USB-Audiointerfaces kann in der Regel verzichtet werden, aber wenn man zur Generierung des Anregungssignals die interne Soundkarte nutzen will (z.B. wenn man ein miniDSP UMIK1 verwendet) dann sollte man peinlichst darauf achten, dass keine Frequenzgangbeeinflussung stattfindet, wie dies bei den eingebauten Soundkarten von Laptops zur Entzerrung der Lautsprecher oder Kopfhörer häufig der Fall ist.
Grundsätzliches Vorgehen:
In unserem Beispiel gehen wir zunächst mal von einem 2-Wege-System mit Tief-/Mitteltöner und Hochtöner aus. Bei einem 3- oder 4-Wege-System ist die Vorgehensweise aber prinzipiell identisch, denn es wird immer ein Chassispaar mit gleichem Setup eingestellt, also z.B. Tieftöner und Mitteltöner. Bei Systemen mit mehr als 2 Wegen wird zunächst immer nur eine Übergangsfrequenz optimiert (z.B. Mitteltöner/Hochtöner) und dann die nächste Übergangsfrequenz (z.B. Tieftöner/Mitteltöner). Bei mehr als 2 Wegen sollte man vorzugsweise mit dem Mitteltöner anfangen (bzw. dem Chassis, welches 1 kHz wiedergeben soll). Dieses Chassis sollte möglichst breitbandig eingesetzt werden - sofern der Frequenzgang, der Klirrfaktor und der maximal erzielbare Schalldruckpegel das erlauben.
1) Positionierung des Lautsprechers:
Zunächst wollen wir nur messen was direkt von den Chassis abgestrahlt wird. Dafür positionieren wir den Lautsprecher möglichst weit weg von allen größeren reflektierenden Flächen, eine kleine 2-Wege-Box also am besten auf einem Ständer ungefähr mitten im Raum. Genau in der Raummitte (Verhältnis 50% zu 50% oder 1:1) wäre übrigens nicht gut, denn dann würden sich die Reflexionen an den gegenüberliegenden Wänden genau addieren -> besser ist immer ein Verhältnis von z.B. 40% zu 60%. Auch ganzzahlige Vielfache wie 33.3% zu 66.7% (= 1:2) oder 25% zu 75% (=1:3) sind ungünstig.
2) Positionierung des Mikrofons:
Um zu messen, was direkt von den Chassis abgestrahlt wird, sollte das Mikrofon möglichst nahe am Lautsprecher positioniert werden, denn dadurch werden die - momentan unerwünschten - Raumrückwirkungen minimiert. Andererseits will man ja den Übergangsbereich zwischen z.B. Tief-/Mitteltöner und Hochtöner optimieren -> das Mikrofon muss also beide Chassis gleich gut messen. Gerade beim Übergang vom (Tief-/) Mittel- zum Hochtöner ist der Einfluss der Schallwand auf den gemessenen Frequenzgang recht groß, man darf also auch nicht zu nah an die Chassis. Bei einer Übernahmefrequenz > 1 kHz wird das Mikrofon daher in ca. 40 cm Abstand in Hauptstrahlrichtung "gleich weit" von beiden beteiligten Chassis positioniert. Der Abstand wird so gewählt, dass er mindestens der doppelten Schallwandbreite (= schmalere Seite der Schallwand) entspricht, bei kleinen Lautsprechern kann man also auch näher herangehen. Dann wird der Einfluss der Schallwand näherungsweise richtig erfasst.
Was bedeutet denn nun "gleich weit"? Als Schallentstehungsort (= SEO) eines Chassis wird das Zentrum seiner Membrane angenommen, als Schallentstehungsebene die Ebene, in der die Schwingspule in die Membrane übergeht. Bei einem Tief-/Mitteltöner liegt diese Ebene oft 2 bis 3 cm tiefer als die Schallwand, bei einem Hochtöner ist dieser Wert oft kleiner. Ziel ist es aber nicht nur, das Mikrofon gleich weit von den beteiligten Chassis zu positionieren, sondern die spätere Wegdifferenz zum Hörplatz nachzubilden. Hier mal eine Prinzipskizze dazu für ein 3-Wege-System:
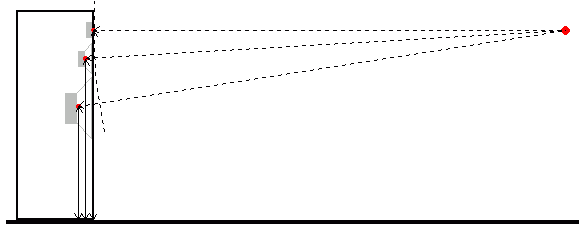
Obwohl der SEO des Mitteltöners nur z.B. 1 cm weiter hinter der Schallwand liegt als der SEO des Hochtöners ist die Wegdifferenz zum 2.5 m entfernten Hörplatz 1.4 cm, weil die Ohrposition auf Höhe des Hochtöners ist und der sich weiter unten befindende Mitteltöner einen weiteren Weg zurücklegen muss. Wenn man das Mikrofon nun näher an die Box rückt muss diese Wegdifferenz von 1.4 cm erhalten bleiben, damit die Phasenverhältnisse so sind wie sie am Hörplatz wären. Diese "zusätzlichen" 4 mm scheinen "vernachlässigbar" zu sein, aber bei einer Trennfrequenz von 4000 Hz ist die Wellenlänge 343 [m/s] / 4000 [Hz = 1/s] = 0.08575 [m] = 8.6 cm, die "zusätzliche" Wegdifferenz von 0.4 cm entspricht also 0.4 [cm] /8.6 [cm] = 0.0465 = 4.65% einer Wellenlänge (= 360°), also 17°. Die "gesamte" Wegdifferenz von 1.4 cm entspricht bei 4000 Hz sogar einer Phasendrehung um 59° -> das Thema ist definitiv nicht zu vernachlässigen.
3) Anregungssignal:
Im Detail empfehlen wir etwas andere Einstellungen als Markus Mehlau, insbesondere um die Reaktion der Messergebnisse auf die Änderungen am t.racks zu beschleunigen:
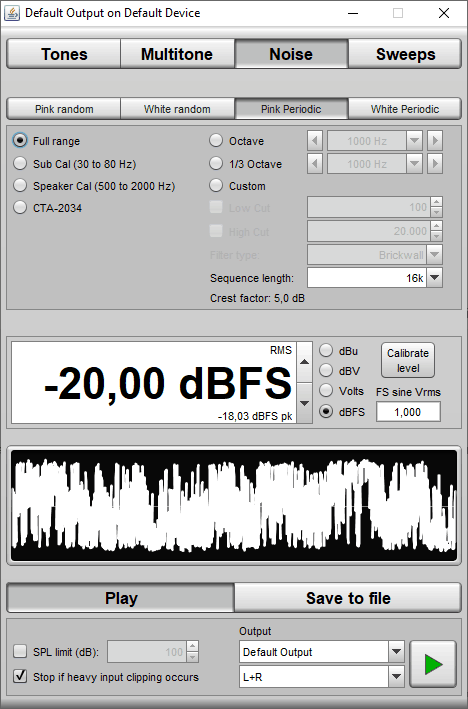
Als Anregungssignal verwenden wir ein periodisches rosa Rauschen (= Pink Periodic) mit einer Sequenzlänge von 16k -> das Rauschen wiederholt sich alle 16384/48000 [Hz] = 0.341 Sekunden. Normalerweise regen wir beide Chassis eines Chassispaares nacheinander mit dem gesamten Frequenzbereich an (= Full range). Das geht auch mit dem Hochtöner ohne Probleme - es sei denn es handelt sich um ein echtes Bändchen mit Übertrager: dann müssen wir den Frequenzbereich nach unten eingrenzen auf ca. 1/3 der geplanten Übernahmefrequenz (z.B. 1 kHz bei einer geplanten Übernahmefrequenz von 3 kHz). Dann checkt man den Eintrag "Custom" und gibt als untere Anregungsfrequenz (= Low Cut) 1000 ein

Wichtig ist allerdings, dass das bei beiden Chassis eines Chassispaares gemacht wird, also auch beim Tief-/Mitteltöner darf dann der Bereich unter 1000 Hz nicht angeregt werden. Denn die Gesamt-Energie des Rauschens bleibt gleich (-20.00 dBFS), wird aber auf einen kleineren Frequenzbereich verteilt -> in unserem Fall ist der Pegel zwischen 1000 und 20000 Hz ca. 5 dB höher als bei Anregung von 20 bis 20000 Hz.
4) RTA-Analyseeinstellungen:
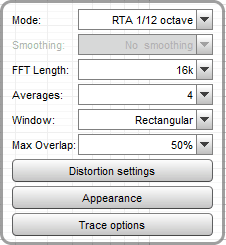
Die Analyseeinstellungen des RTA-Moduls müssen natürlich zum Anregungssignal passen:
-
• die "FFT Length" muss identisch mit der "Sequence length" des Generator-Moduls sein -> 16k
-
• das "Window" muss "Rectangular" sein, da wir im Generator-Modul periodisches Rauschen gewählt haben
-
• "max. Overlap" darf 50% sein, dann wird die Anzahl der gewählten Mittelungen doppelt so schnell erreicht, weil 50% der Messdaten "recycelt" werden
-
• "Averages" darf 4 sein, dann werden Änderungen der Filter bereits nach 2.5 * 16384 / 48000 [Hz = 1/s] = 0.85 s vollständig angezeigt - also ohne spürbare Verzögerung
-
• als "Mode" muss "RTA 1/x octave" gewählt werden, damit bei rosa Rauschen ein linearer Frequenzgang angezeigt wird; wir empfehlen eine Auflösung von 1/12- oder 1/6-Oktave
5) RTA-Messung:
Tja, und dann kann es eigentlich losgehen, z.B. mit der Messung des Tief-Mitteltöners (= TMT). Dazu startet man den Generator (man klickt im Generator-Modul rechts unten auf den grünen Wiedergabe-Pfeil) und startet die Messung im RTA-Modul, indem man auf den dunkelroten "Aufnahme-Knopf" klickt. Der wird dann hellrot und zeigt an, dass die Aufnahme läuft. Wenn sich das Messergebnis nach ein paar Mittelungen stabilisiert hat stoppt man die Messung - indem man auf den hellroten "Aufnahme-Knopf" klickt, der dann wieder dunkelrot wird. Wenn man mit der Messung zufrieden ist kann man sie speichern, indem man auf das Disketten-Symbol mit der Bezeichnung "Current" klickt. Dann wurde die Messung aber noch nicht auf die Festplatte gespeichert (es wird ja auch nicht nach dem gewünschten Dateinamen gefragt) sondern ist erst mal "nur" im Hauptmodul von REW verfügbar. Als nächstes sollte man die Messung dort erst mal vernünftig "beschriften", damit man später noch weiß, was man da gemessen hat. Denn REW schreibt standardmäßig nur das Datum und die Uhrzeit in das Beschreibungsfeld. Die dort eingetragene Beschreibung wird später auch bei der Darstellung der Kurven verwendet, und da wäre "TMT 40cm/0°, ohne Filter" doch sicher passender als "Jun 4 16:05:12"- oder?
Jetzt könnte man natürlich nach Lust und Laune an den Einstellungen des t.racks DSP 4x4 Mini Amp herumspielen bis einem das Ergebnis gefällt. Diese "Spielphase" sollte man sich auch zu Anfang mal "gönnen", damit man ein Gefühl dafür kriegt was die einzelnen Einstellungen so machen.
Aber irgendwann möchte man z.B. eine akustische Trennfrequenz von 2000 Hz mit einer akustischen Filtersteilheit von 24 dB/Oktave mit Linkwitz-Riley-Charakteristik erreichen. Und da wäre es doch schön, wenn REW einem diese Zielkurve schon als Vorgabe ins Diagramm malen würde und man sich daran orientieren könnte, oder? Und noch schöner wäre es, wenn man nicht andauernd Krach machen und messen müsste, sondern REW einem das Ergebnis vorausberechnet, oder? Genau das geht im Modul EQ (und noch einiges mehr). Dazu wählt man im Hauptmodul die gewünschte Messung aus (z.B. "TMT 40cm/0°, ohne Filter") und öffnet das EQ-Modul. Im oberen Teil des EQ-Moduls wird nun diese Messung angezeigt (violett + magenta) - und noch eine 2. Kurve: wo kommt die denn her? Das ist die Zielkurve - halt nur noch nicht die richtige ;-). Aber am rechten Rand des EQ-Moduls gibt es ja einige Reiter mit vielen Einstellmöglichkeiten . . .
1) Equaliser:
Hier wählen wir aus, welchen "Equaliser" REW nachbilden soll. Denn nicht alle "Equaliser" haben die gleichen Einstellmöglichkeiten (Anzahl der viele Filter, Filtercharakteristik und -steilheit etc.) und nicht alle interpretieren die Einstellparameter gleich :-(
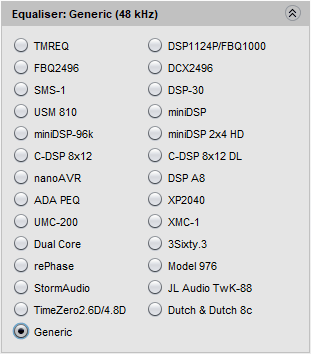
Da der t.racks DSP 4x4 Mini Amp momentan dort noch nicht gelistet ist nehmen wir den "Generic" - also den "allgemeingültigen".
2) Target Settings:
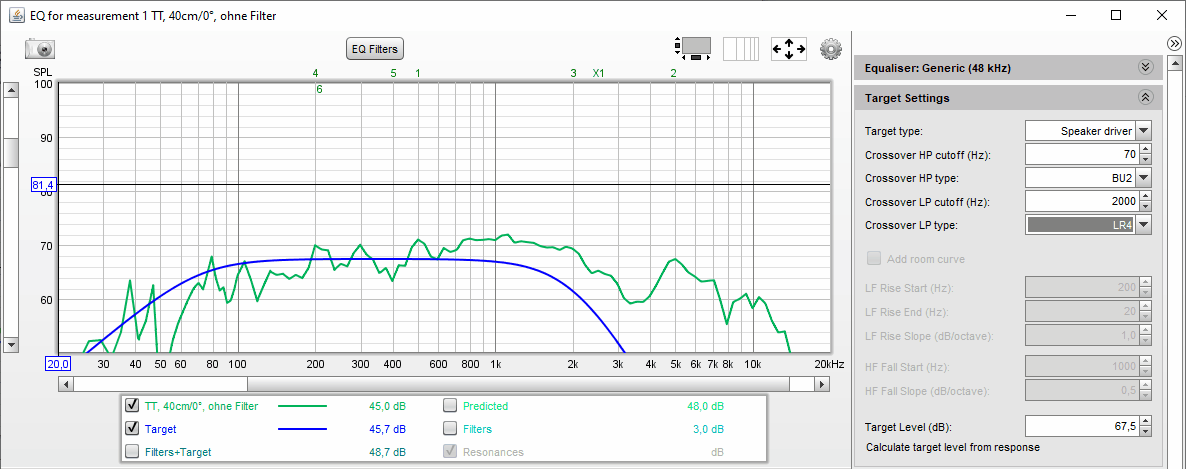
Als nächstes wollen wir die richtige Zielkurve (= Target) einstellen. Das machen wir im Abschnitt "Target Setting". Als "Target type" wählen wir in unserem Falle (TMT) "Speaker driver". Wenn wir jetzt die gewünschten Hochpass-Filterfunktion (= Crossover HP type) und Tiefpass-Filterfunktion (= Crossover LP type) auf "None" setzen und im Feld "Target Level (dB)" 80 eingeben, sollte der obere Grafikbereich des EQ-Moduls so aussehen:
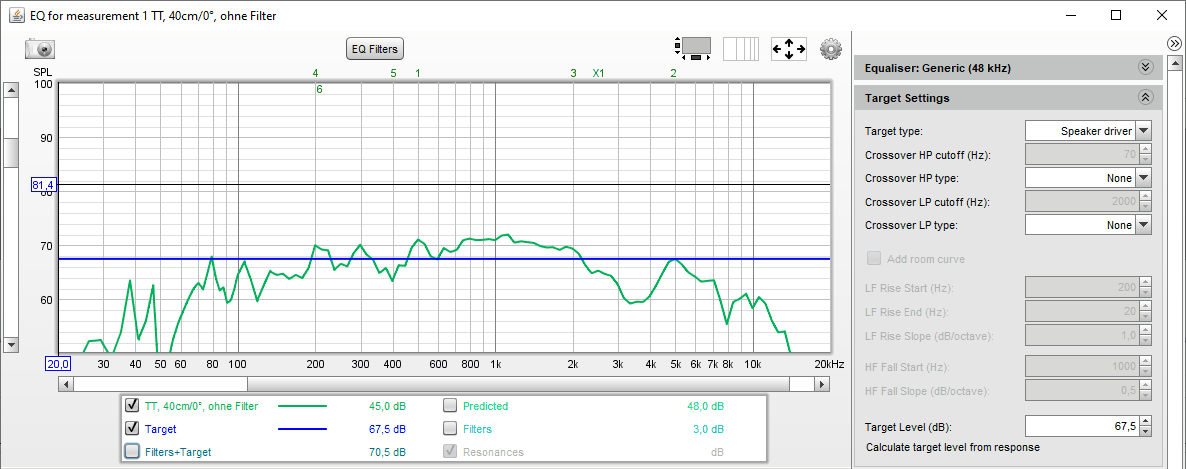
Wenn die Kurve NICHT gerade verläuft habt ihr im REW-Hauptmodul in den "Preferences" im Reiter "House Curve" eine "Lieblingskurve" geladen, die ihr durch Klicken auf die Schaltfläche "Clear Curve" unberücksichtigt lassen solltet.
Na, dann geben wir für unseren TMT mal einen Tiefpass bei 2000 Hz mit einer Steilheit von 24 dB/Oktave und Linkwitz-Riley-Charakteristik als Zielkurve vor:
Die Auswahlbox erlaubt nur sehr kryptische Wahlmöglichkeiten:
| Bezeichnung | Filtercharakteristik | Filtersteilheit |
| None | kein Filter | 0 dB/Oktave |
| BE2 bis BE8 | Bessel | Filterordnung 2 bis 8 -> 12 bis 48 dB/Oktave |
| BU1 bis BU8 | Butterworth | Filterordnung 1 bis 8 -> 6 bis 48 dB/Oktave |
| LR2 bis LR8 | Linkwitz-Riley | Filterordnung 2 bis 8 -> 12 bis 48 dB/Oktave |
3) Filter Tasks:
Wenn sich den die Einstellmöglichkeiten im Reiter "Filter Tasks" so anguckt könnte man doch glatt auf die Idee kommen, dass REW die optimalen Filter automatisch einstellen kann ("Match response to target"):
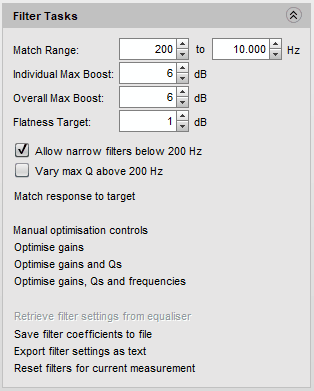
Das funktioniert bei einer "Über-Alles-Optimierung" auch ganz gut, bei Einzelchassis sind unsere Erfahrungen eher negativ (man muss auf jeden Fall auch im Abschnitt "Crossover filters" die Hoch- und Tiefpassfilter von Hand vorgeben). Aber zum Glück kann man das auch manuell machen. Dazu öffnet man den Dialog "EQ-Filters" durch klicken auf die gleichnamige Schaltfläche.
4) Schaltfläche EQ-Filters:
Folgende Filter können beim "Generic"-Equaliser simuliert werden:
| Bezeichnung | Bedeutung | Eingabewerte |
| None | kein Filter | - |
| PK (Peak) | Parametrischer EQ | Frequenz [Hz], Verstärkung/Gain [dB], Güte/Q [-]) |
| LP (Low Pass) | Tiefpass (Butterworth, 12 dB/Oktave) | Frequenz [Hz] |
| HP (High Pass) | Hochpass (Butterworth, 12 dB/Oktave) | Frequenz [Hz] |
| LP1 (Low Pass, order 1) | Tiefpass (Butterworth, 6 dB/Oktave) | Frequenz [Hz] |
| HP1 (High Pass, order 1) | Hochpass (Butterworth, 6 dB/Oktave) | Frequenz [Hz] |
| LPQ (Low Pass, variable Q) | Tiefpass (12 dB/Oktave, variable Güte) | Frequenz [Hz], Güte/Q [-]) |
| HPQ (High Pass, variable Q) | Hochpass (12 dB/Oktave, variable Güte) | Frequenz [Hz], Güte/Q [-]) |
| LS (Low Shelv) | Bass-Anhebung/-Absenkung (2. Ordnung, Q=0.7) | Frequenz [Hz], Verstärkung/Gain [dB] |
| HS (High Shelv) | Höhen-Anhebung/-Absenkung (2. Ordnung, Q=0.7) | Frequenz [Hz], Verstärkung/Gain [dB] |
| LS 6 dB (Low Shelv, order 1) | Bass-Anhebung/-Absenkung (1. Ordnung) | Frequenz [Hz], Verstärkung/Gain [dB] |
| HS 6 dB (High Shelv, order 1) | Höhen-Anhebung/-Absenkung (1. Ordnung) | Frequenz [Hz], Verstärkung/Gain [dB] |
| LS 12 dB (Low Shelv, order 2) | Bass-Anhebung/-Absenkung (2. Ordnung, Q=1) | Frequenz [Hz], Verstärkung/Gain [dB] |
| HS 12 dB (High Shelv, order 2) | Höhen-Anhebung/-Absenkung (2. Ordnung, Q=1) | Frequenz [Hz], Verstärkung/Gain [dB] |
| LSQ (Low Shelv, variable Q) | Bass-Anhebung/-Absenkung (2. Ordnung, variable Güte) | Frequenz [Hz], Verstärkung/Gain [dB], Güte/Q [-] |
| HSQ (High Shelv, variable Q) | Höhen-Anhebung/-Absenkung (2. Ordnung, variable Güte) | Frequenz [Hz], Verstärkung/Gain [dB], Güte/Q [-] |
| NO (Notch) | Kerb-Filter | Frequenz [Hz] |
| AP (Allpass) | Allpass | Frequenz [Hz], Güte/Q [-] |
Mit wenigen Filtern konnten wir so den Frequenzgang des Tieftöners gemäß der Zielkurve linearisieren:
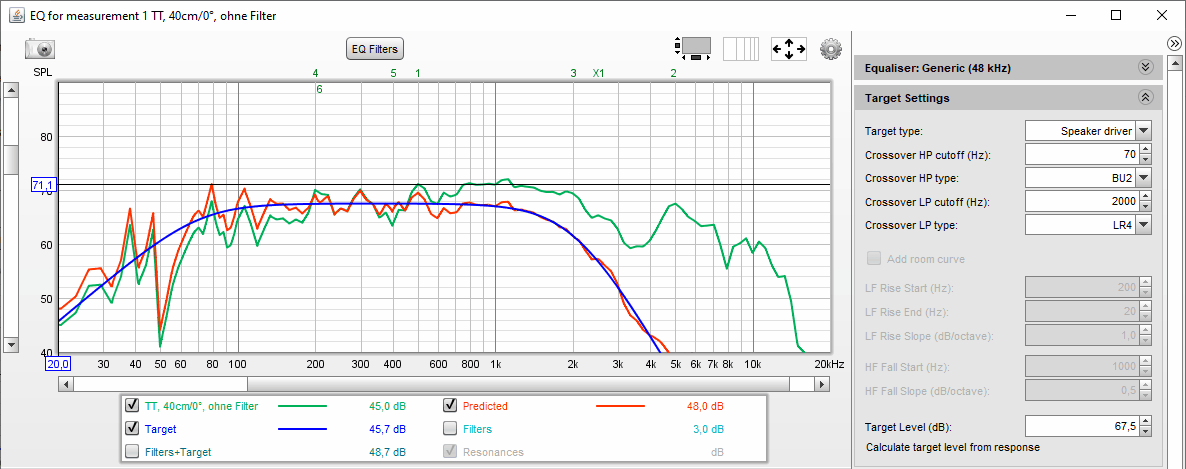
Und so sehen die zugehörigen manuell ermittelten Filter-Einstellungen aus:
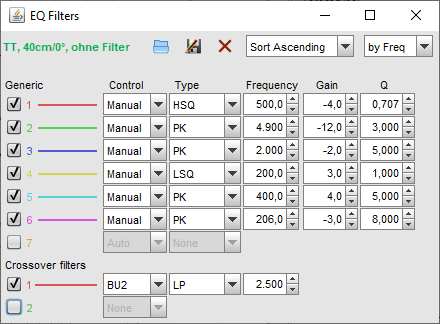
Nachdem man die Filter (von Hand oder automatisch) optimiert hat und mit dem Ergebnis zufrieden ist (mindestens bis 20 dB unter dem Target Level muss die Abweichung < +/- X/10 dB bleiben, also z.B. +/- 1 dB bei -10 dB) muss man die gefundenen Filter von Hand in die Software des t.racks DSP 4x4 Mini Amp übertragen. Wenn man REW und die t.racks DSP mini-Software gleichzeitig anzeigen lassen will wird es eng auf nur einem Bildschirm mit 1920 x 1080 Punkten Auflösung:
+t.racksSW.jpg)
Es ist ratsam das gerade optimierte Chassis noch einmal im Modul RTA zu messen, die Messung abzuspeichern (sinnvolle Bezeichnung nicht vergessen ;-)), im REW-Hauptmodul auszuwählen und das EQ-Modul erneut zu starten: im Idealfall verläuft die Messung nun nah an der Zielkurve (wenn sich die "Equaliser"-Hardware so verhält wie REW denkt):
-> Volltreffer!
Dasselbe machen wir jetzt mit dem Hochtöner:
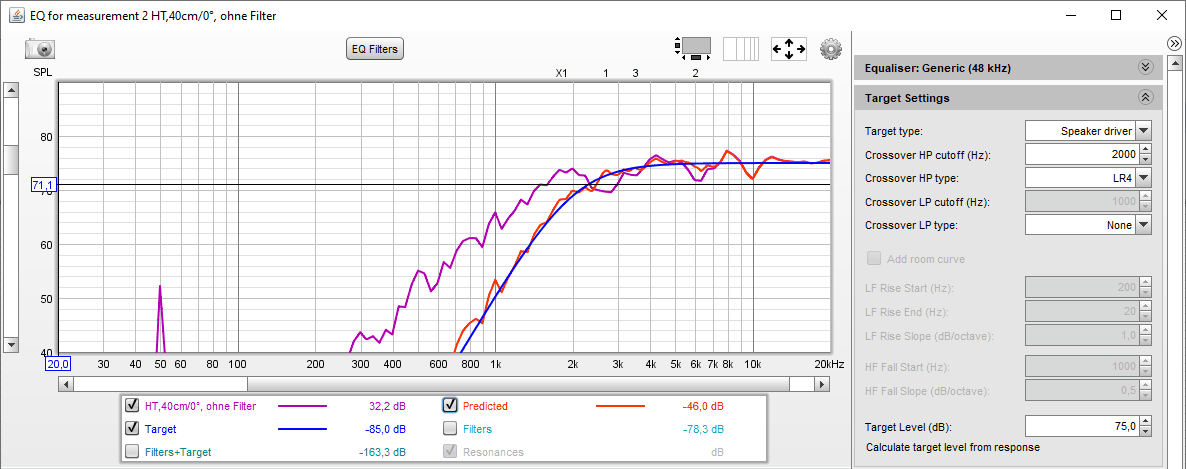
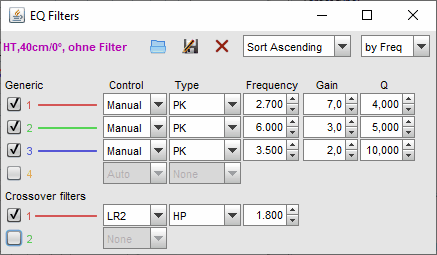
Und so sehen die zugehörigen manuell ermittelten Filter-Einstellungen aus (es werden nur 3 PEQs benötigt):
Und so die Nachmessung (die Störungen bei 8 und 10 kHz haben wir mal nicht entzerrt, s.u.):
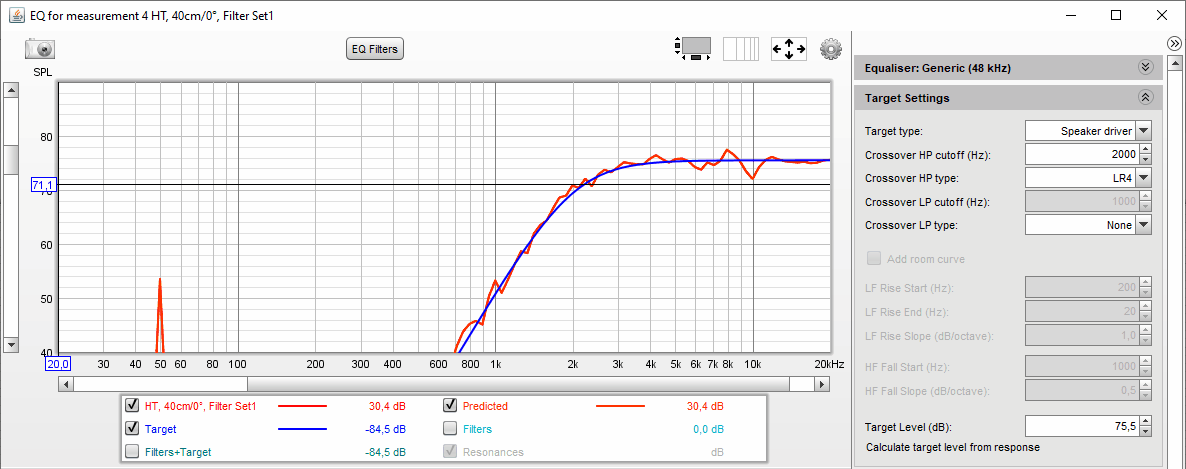
-> noch ein Volltreffer!
Hinweis: obwohl die Zielfunktion eine Steilheit von 24 dB/Oktave hatte (Linkwitz-Riley-Charakteristik) reichten in beiden Fällen elektrische Filtersteilheiten von 12 dB/Oktave mit Butterworth-Charakteristik um die akustische Filtersteilheit von 24 dB zu erzielen!
Optimierung des Übergangsbereichs für ein Chassispaar:
Nachdem man beide Chassis (Tief-/Mitteltöner TMT und Hochtöner HT) auf diese Weise getrennt der Zielkurve angenähert hat kommt der spannende Moment: wie überlagern sich die Chassis im Übernahmebereich? Dazu kommt es auf die relative Phasenlage an - und die haben wir bisher geflissentlich ignoriert. Das Schöne an der Zielfunktion Linkwitz-Riley mit einer Steilheit von 24 dB/Oktave ist:
-
• dass der Übernahmebereich wegen der großen Steilheit (24 dB/Oktave) und trotz des "sanften" Übergangs (Linkwitz-Riley-Charakteristik) relativ schmal ist (etwa +/- 1 Oktave)
-
• dass sich (theoretisch) nur dann ein linearer Summenfrequenzgang ergibt, wenn sich die Chassis zu 100% konstruktiv addieren
Wenn beide Chassis perfekt der Zielfunktion folgen (und gleich gepolt sind) bleibt als letzte Stellschraube die Laufzeitdifferenz (bei der Software des t.racks DSP 4x4 Mini Amp im Reiter "Delay" einzustellen). Man macht also eine "Dauer-Messung" im RTA-Modul und verstellt die Verzögerung des Hochtöners (ausgehend von 0 ms) so lange, bis der Frequenzgang optimal linear ist (Dank der geringen Mittelungsanzahl sieht man die Auswirkungen der Änderung des Delays quasi in Echtzeit). Sollte das nicht klappen muss entweder der Tief-/Mitteltöner verzögert werden (das ist aber üblicherweise nicht der Fall, außer z.B. bei Hochtonhörnern) oder die Zielfunktionen waren nicht gut genug erreicht worden.
Und so sieht der gemessene Frequenzgang von beiden Chassis nach Verzögerung des Hochtöners um 4 Abtastwerte (=4/48000 [Hz=1/s]=0.0000833 [s] bzw. 343 [m /s] * 0.0000833 [s] = 0.0286 m = 2.86 cm) aus:
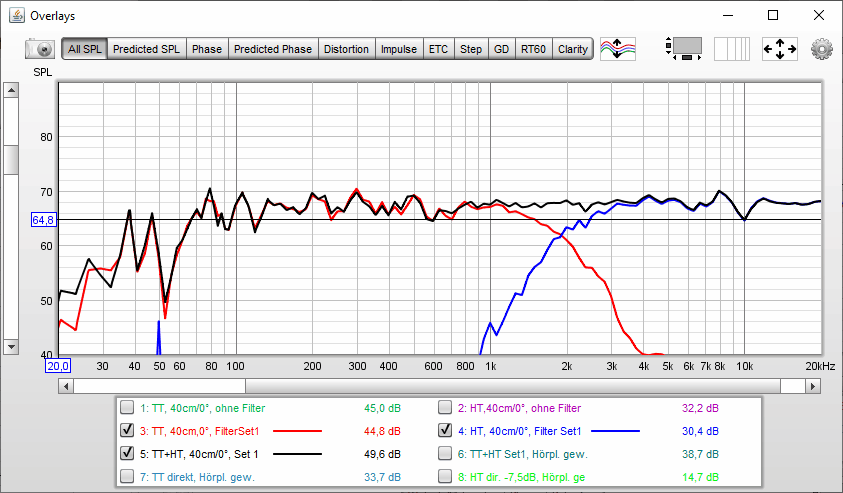
-> und schon wieder ein Volltreffer!
Optimierung des Übergangsbereichs für das nächste Chassispaar:
Bei einer 3-Wege-Box hätten wir nun den Mitteltöner (MT) und Hochtöner (HT) optimiert - jetzt käme also der Tieftöner (TT) dran. Hier ändert sich die Vorgehensweise etwas, weil bei den üblicherweise relativ tiefen Übernahmefrequenzen von z.B. 400 Hz die Raumrückwirkungen deutlich ansteigen -> man möchte mit dem Mikrofon näher an die Chassis heran. Andererseits ist der Einfluss der Schallwand im Übernahmebereich nicht mehr sooo kritisch (nur geringe und eher gleichmäßige Änderung über der Frequenz) und die Richtwirkung der Chassis und der Einfluss von Laufzeitunterschieden ist gering. Daher positioniert man das Mikrofon in ca. 10 bis 15 cm Abstand von der Schallwand und sucht einen Punkt, der gleich weit (mit dem Zollstock gemessen) vom Mittelpunkt der beiden Chassis entfernt ist. Üblicherweise misst man die Chassis dann unter 45°, aber im Übernahmebereich (und NUR um den geht es bei dieser Übung) spielt das nur eine geringe Rolle.
Die Optimierung läuft nach obigem Schema ab. Es gibt nur zwei Besonderheiten zu bedenken:
• wenn der Mitteltöner leiser gemacht werden muss, dann muss anschließend auch der Hochtöner um diesen Betrag leiser gemacht werden, damit der Übergang zum Hochtöner wieder stimmt
• wenn der Mitteltöner gegenüber dem Tieftöner verzögert werden muss, dann muss anschließend auch der Hochtöner um diesen Betrag zusätzlich verzögert werden, damit der Übergang zum Hochtöner wieder stimmt
Subjektive Beurteilung des "Verschmelzungsgrades":
Wenn die Übergänge aller Chassispaare nach diesem Schema optimiert wurden sollte sich der Gesamt-Lautsprecher schon ganz gleichmäßig anhören. Zu diesem Zeitpunkt nutzen wir gerne den Rauschgenerator von REW mit "richtigem" rosa Rauschen (also nicht mehr das periodische rosa Rauschen) und bewegen uns in ca. 50 cm Abstand vor der Box auf und ab. Dabei merkt man schon, dass sich die "Klangfarbe" des Rauschens verändert - das ist "normal", denn man verändert durch das auf- und abbewegen ja ständig die relativen Abstände zu den Chassispaaren und damit die relative Phasenlage.
Wenn die Ohrhöhe in der Mitte der jeweiligen Chassispaare (z.B. MT und HT) liegt sollte man sich vorstellen können, dass das gemeinsame Rauschen des Chassispaares (bei einer 3-Wege-Box ggf. z.B. den Tieftöner muten):
-
1) alles aus dem Hochtöner kommt
-
2) alles aus dem Mitteltöner kommt
-
3) aus der Mitte zwischen den beiden Chassis kommt
Wenn man nicht das Gefühl hat, dass die Höhen alle aus dem Hochtöner kommen und die Mitten alle aus dem Mitteltöner (die Rauschanteile also "getrennt" hört) ist man auf dem richtigen Weg. Optimal ist es, wenn sich die Vorstellung "3" am realistischsten "anfühlt", die beiden Chassis also klanglich "verschmolzen" sind.
Subjektive Beurteilung am Hörplatz:
Bisher haben wir die Box gemessen/optimiert - aber den Hörraum weitgehend ausgeblendet. "Dummerweise" hört sich ein und derselbe Lautsprecher in verschiedenen Hörräumen (oder aber an verschiedenen Lautsprecher- bzw. Hörpositionen in demselben Hörraum) deutlich anders an. Wir hören eben nicht nur den Schall, der auf dem kürzesten Weg vom Lautsprecher zu unseren Ohren kommt (sog. Direktschall) sondern auch Reflexionen an den Raumbegrenzungsflächen (sog. Diffusschall). Im Mittel- und Hochtonbereich beeinflussen diese Reflexionen vor allem die räumliche Abbildung (im Idealfall stehen (fast immer mittig aufgenommene) Sänger fest umrissen in der Mitte zwischen den Lautsprechern), im Bass- und Grundtonbereich kommt es durch Mehrfachreflexionen an gegenüberliegenden Wänden zu ausgeprägten Stehwellenmustern mit "Schalldruck-Bergen" (= Orte hoher Lautstärke, oft mehr als 10 dB lauter als der Mittelwert) und "Schalldruck-Tälern" (= Orte geringe Lautstärke, oft mehr als 10 dB leiser als der Mittelwert).
Das führt im Endergebnis dazu, dass ein Lautsprecher mit perfekt linearem Frequenzgang unter idealen Messbedingungen (z.B. im "schalltoten" Raum) in einem realen Hörraum Frequenzgangschwankungen von +/- 10 dB unter 500 Hz aufweist - und sich dort alles andere als linear und ausgewogen anhört. Als "normaler" HiFi-Interessierter kann man nur versuchen durch eine andere Lautsprecheraufstellung und/oder die Wahl eines anderen Hörplatzes diese Schwankungen zu reduzieren - wenn das denn möglich ist. Man kann auch versuchen den Hörraum durch Absorberelemente zu verbessern - wenn das denn möglich und ästhetisch und finanziell tolerabel ist. Meist bleibt nur das Herumdoktern an Nebenschauplätzen wie Lautsprecherkabel, Spikes etc., die das Stehwellenproblem nicht an der Wurzel packen und daher nur gering beeinflussen können.
Mit dem t.racks DSP 4x4 Mini Amp gibt es aber die Möglichkeit, den Lautsprecher auch an den Raum anpassen zu können. Vor allem die besonders störenden Überhöhungen im Bassbereich lassen sich so deutlich entschärfen, die Musik wird besser durchhörbar, da die tiefen Frequenzen die besonders wichtigen mittleren Frequenzen nicht mehr "zukleistern".
Messungen am Hörplatz:
Dazu misst man die Box mit den einzeln optimierten Übergangsbereichen nun mit allen gefilterten Chassis am Hörplatz - und wundert sich. Was vorher in 40 cm Abstand noch so schön linear war fällt nun - mehr oder weniger gleichmäßig - zu hohen Frequenzen hin ab und schwankt im Bass- und Grundtonbereich gravierend. Außerdem misst man ja an allen benachbarten Positionen auch noch etwas anderes - was ist denn da jetzt "richtig"?
Da empfehlen wir das Mikrofon von Hand um die gedachte Kopfposition herumzuwedeln, wobei das Mikrofon immer nach vorne zeigt und:
-
• ca. +/- 30 cm in der Breite,
-
• +/- 20 cm in der Tiefe
-
• und +/- 10 cm in der Höhe zu variieren
Das entspricht also z.B. einer 18° schrägen, 40x60 cm großen, liegenden Ellipse. Die Umlaufzeit einer Ellipse sollte etwa 3 Sekunden betragen, es sollten insgesamt ca. 8 Umläufe gemittelt werden. Wenn man die RTA-Parameter wie folgt ändert:
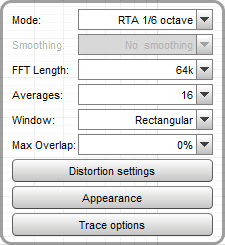
sollte eine Umdrehung 2 Wiederholungen des periodischen Rauschen (=2 * 65536/48000 [Hz = 1/s] = 2.73 [s]) dauern, nach 16 Mittelungen (ohne Overlap) sind 8 Umdrehungen fertig. Danach muss man nur auf die Leertaste drücken um die Messung zu beenden - das sollte auch im Blindflug klappen. Beim Messen muss man aufpassen, dass das Mikrofonkabel nirgendwo anstößt -> am besten über die Schulter legen.
Diese Messungen sind bereits nach wenigen "Trainingsrunden" erstaunlich gut reproduzierbar - probiert es einfach mal aus (mehrere Versuche abspeichern und im Overlay-Modul übereinanderlegen). Das Ergebnis wird wieder abgespeichert ("sinnvollen" Namen vergeben, z.B. "BoxL, Hörplatz, Filter V1") und im EQ-Modus wird eine neue Zielkurve generiert. Diesmal wird ja der "Full range speaker" entzerrt, wodurch neue Eingabefelder editierbar werden, wenn man "Add room curve" aktiviert:
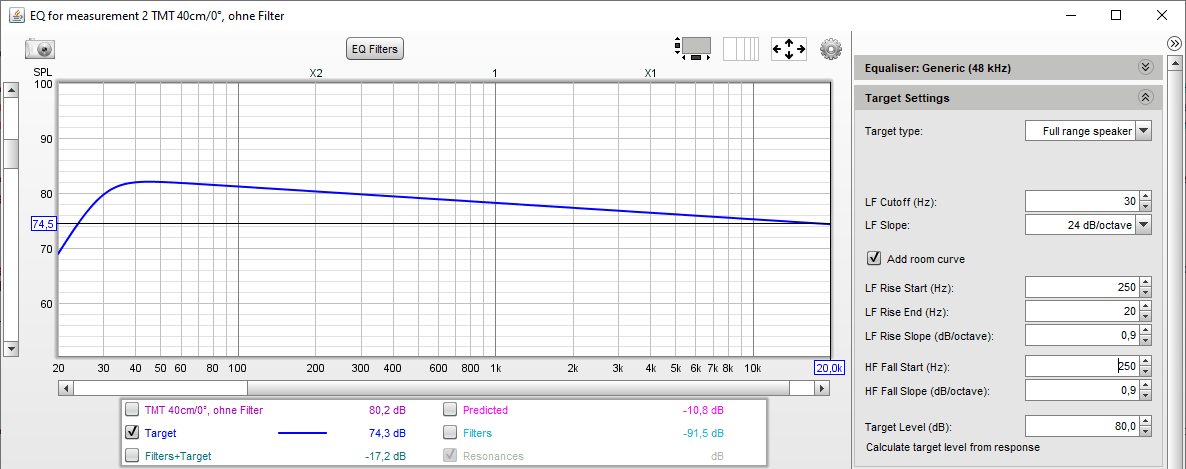
-> wir bevorzugen in unserem Hörraum einen kontinuierlichen Abfall von 0.9 dB/Oktave = 0.3 dB/Terz = 3 dB/Dekade
-> Alternativ kann man im REW-Hauptmodul unter "Preferences" im Reiter "House Curve" eine entsprechende Zielkurve laden
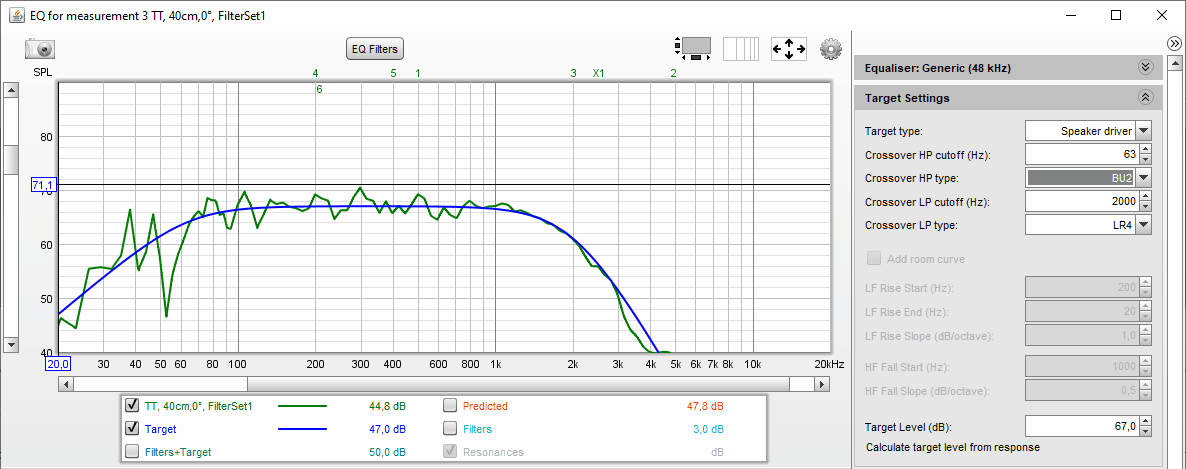
Und so misst sich unser "40cm-Volltreffer" am Hörplatz:
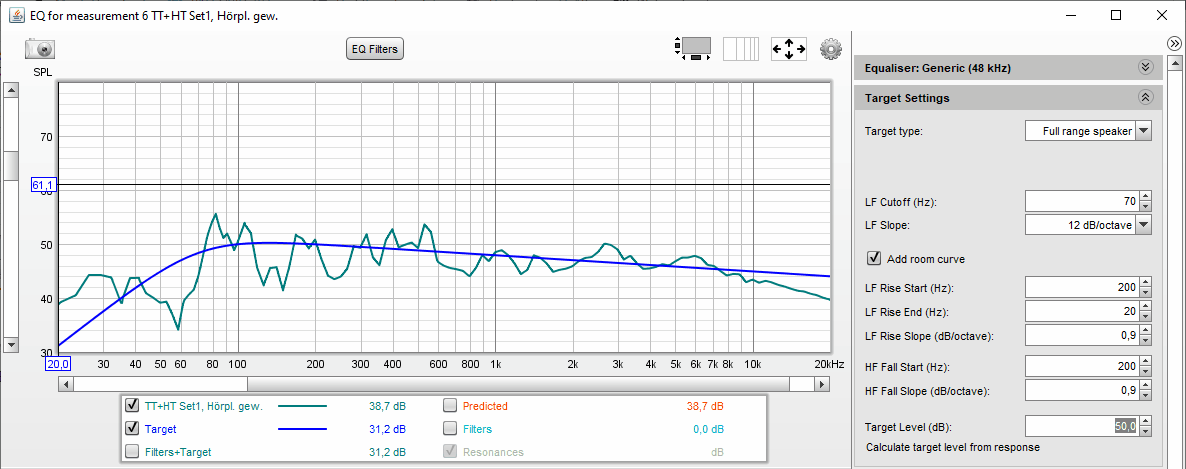
-> das sieht gar nicht mehr so gut aus :-(
Was auffällt:
-
• die nicht korrigierte Störung des Hochtöners bei 8 und 10 kHz ist futschikato
-
• dafür gehen die bei 40 cm Abstand (scheinbar) benötigten Entzerrungen bei 2.7 kHz (+7 dB, Q=4) und 6 kHz (+3 dB, Q=5) nach hinten los (am Hörplatz gibt es dort nun unerwünschte Überhöhungen)
-
• im Bass- und Grundtonbereich kommen erwartungsgemäß Raumeinflüsse hinzu (z.B. Einbruch bei 250 und um 700 Hz)
Da könnte man doch glatt auf die Idee kommen, dass eine Optimierung in 40 cm Abstand vielleicht doch nicht der richtige Startpunkt ist und man die oben geschilderte Strategie (Messung mit Filtern an Zielkurve annähern) doch eher mit Messungen am Hörplatz machen sollte. Dann muss man aber mit einer entsprechenden House Curve arbeiten (z.B. HouseCurve_Icy.txt), damit der Frequenzgang wie gewünscht am Hörplatz abfällt. Dann sehen die simulierten Ergebnisse (Filter Set 2) so aus:
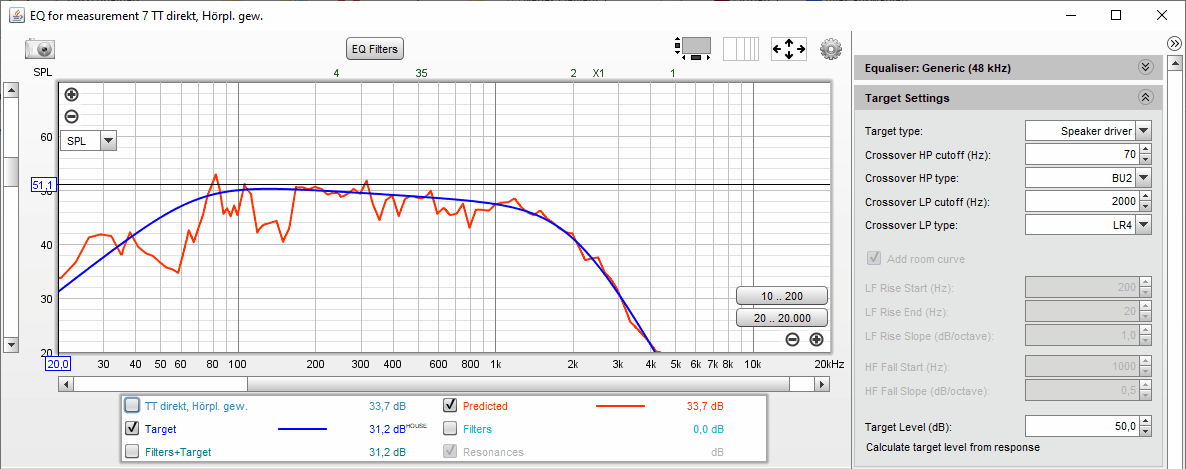
Teilnehmer unseres 2-tägigen Workshops "DSP-Weichen einstellen" wissen, welche Methode wir bevorzugen . . .
Strategie für die Optimierung am Hörplatz:
Sowohl beim Abbau der Überhöhungen als auch beim Auffüllen der Einbrüche hören wir uns rosa Rauschen am Hörplatz an und beurteilen:
-
• ob die Änderung hörbar ist (Effekt einzeln ein- und ausschalten)
-
• ob sich das Rauschen "gleichmäßiger" anhört (= weniger Töne heraushörbar sind)
Im Idealfall sollten keine tonalen Verfärbungen hörbar sein und sich das Rauschen sehr gleichmäßig anhören. Besonders die Überhöhungen sind leicht als "zusätzliche Töne" herauszuhören, die Einbrüche machen sich oft erst beim Ein- und Ausschalten der "Füllungen" bemerkbar.
Wenn sich das Rauschen ausgewogen anhört geht es mit "bekannter" Musik weiter. "Bekannte" Musik sind idealerweise "gute" Aufnahmen, die ihr schon auf vielen Anlagen gehört habt und gut kennt. Wir verwenden unter anderem diese Stücke (s. Musik "vergleichen" mit dem Waveanalyzer). Aber ihr müsst euch schon eure eigene "Playlist" basteln und zur Beurteilung des Bassbereichs auch mal einen guten Kopfhörer aufsetzen - der kennt nämlich keine Raummoden . . .
Ein paar Worte zum Musik hören ohne dröhnende Bässe:
Wenn man die Dröhnfrequenzen im Bassbereich mit PEQs abgesenkt hat, damit es sich gut misst, mag sich das Ergebnis für viele zunächst bassschwach anhören - schließlich hat man sich sein gesamtes HiFi-Dasein an diese immer irgendwie dröhnenden Bässe gewöhnt. Aber wenn man mal ein paar Tage "ohne" Raummoden gehört hat und diese dann wieder zulässt (das geht mit der Software des t.racks DSP 4x4 Mini Amp ja sehr einfach) werden die dröhnenden Bässe von den meisten Leuten als sehr störend empfunden, weil sie oft wichtige musikalische Informationen in den darüber liegenden Frequenzbereichen "zukleistern".
Viele Leute fürchten, dass bei einem "typischen" Raummoden-"Killer" von F=40 Hz, Q=10, Gain=-10 dB dann ja auch der Direktschall 10 dB zu leise ist. Das ist aber zumindest bei transienten Vorgängen nicht der Fall. Hier wird mal ein Signal ähnlich dem Anschlag einer Trommel gezeigt (exponentiell abklingender Sinus von 40 Hz):
.png)
Und so sieht das Anregungssignal aus, wenn ein parametrischer Equalizer mit einer Mittenfrequenz von 40 Hz, eine Güte von 10 und einer Verstärkung von -10 dB dazwischengeschaltet wird:
+PK40,Q10,-10dB.png)
Das "Anschwingen" des Tones wird nur sehr gering von 98.1% auf 89.8% reduziert (- 0.77 dB), aber nach 4 Schwingungen schon von 78.4% auf 29.3% (= -8.53 dB) -> das Signal klingt also deutlich schneller ab. Die Idee ist ja gerade, dass die "fehlende, spätere" Anregungsenergie von den Reflexionen nach und nach aufgefüllt wird: im Idealfall ähnelt die Summe aus (gefiltertem Direktschall + Reflexionen) dann dem ungefilterten Direktschall (mehr dazu in einem Folgeartikel).
Fazit:
DSP-Weichen einstellen ist mit dieser Anleitung so einfach wie Malen nach Zahlen. Wir haben schon Dutzende von Lautsprechern aktiviert, und IMMER klang die aktivierte Variante deutlich ausgewogener als die passive, wenn wir den größten Vorteil der Aktivierung mit DSP-Weichen genutzt haben: dass der Lautsprecher an den Hörraum angepasst werden kann!!!
Wichtig bei der Abstimmung ist, dass man nicht nur misst, sondern auch "bekannte" Musik subjektiv beurteilt - denn Messen und Hören sind halt 2 Paar Schuhe. Die Messtechnik ermöglicht relativ einfach ca. 90% des Klangpotenzials auszuschöpfen - die letzten Prozente sind nur durch subjektive Beurteilung machbar.
Unsere ersten Erfahrungen mit dem t.racks DSP 4x4 Mini Amp sind sehr gut: die Software lässt sich relativ einfach bedienen, und der Verstärker hat selbst für den relativ "leisen" Tieftöner unser Testbox (MONACOR SPH-135C) genug Power: bei Marla Glens "Personal" hatten wir bei +/- 4 mm Hub im kleinen 6 Liter-Gehäuse schon fast Angst um die Bässe - der Verstärker hat dabei nicht mal angedeutet, dass er sich anstrengen müsste! Die 50 Watt/Kanal an 8 Ohm landen ja auch zu 100% im Chassis und werden nicht in der Frequenzweiche "verbraten" . . .

Jetzt fragen wir uns nur, ob es bei so preiswerter und dabei leistungsfähiger Elektronik wie dem t.racks DSP 4x4 Mini Amp überhaupt noch Sinn macht Bauvorschläge mit passiven Weichen zu entwickeln - bei den aktuell in schwindelerregende Höhen steigenden Preisen für Spulen und Kondensatoren . . .
Unsere Abonnenten können hier die REW-Messungen (V5.20) und die ermittelten Filter-Sets herunterladen (ZIP-Datei, 1.4 MB), um die Vorgehensweise ohne eigene Messungen nachzuvollziehen.)
Kommentare
Bei immer paarweise symmetrischen Chassis bleibt man beim Messen immer auf HT-Hoehe, richtig?
Ich habe über das amerikanische avnirvana Forum gerade noch folgendes herausgefunden, bitte um Nachsicht wenn das schon bekann ist.
Mir hat das jedenfalls noch gefehlt, wie kann ich im RTA direkt die Zielkurve anzeigen lassen und live am DSP kurbeln ohne die Messung unterbrechen zu müssen.
"You can use the option to "Generate measurement from target shape" on the Target settings panel and select that measurement in the main REW window, it will then be available on the RTA as the first trace in the legend."